# 2.1 善用设计模式
本章主要介绍与软件设计相关的性能优化方法和思想。软件的结构对系统整体性能有着重要的影响。优秀的设计结构可以规避很多潜在的性能问题,对系统性能的影响可能远远大于代码的优化。因此熟悉一些常用的软件设计模式和方法,对设计高性能软件有着重要的帮助。本章着眼于设计优化,主要讲解了一些常用的与性能相关的设计模式、组件和设计方法。
本章涉及的主要知识点有:
- 单例模式的使用和实现
- 代理模式的实现和深入剖析
- 享元模式的应用
- 装饰者模式对性能组件的封装
- 观察者模式的使用
- 使用 Value Object 模式减少网络数据传输
- 使用业务代理模式添加远程调用缓存
- 缓冲和缓存的定义和使用
- 对象池的使用场景及其基本实现
- 构建负载均衡系统以及Terracotta框架的简单使用
- 时间换空间和空间换时间的基本思路
设计模式是前人工作的总结和提炼。通常,被人们广泛流传的设计模式都是对某一特定问题的成熟的解决方案。如果能合理的使用设计模式,不仅能使系统更容易被他人理解,同时也能使系统用友更加合理的结构。本节总结归纳了一些景点的设计模式,并详细说明它们与软件性能之间的关系。
# 2.1.1 单例模式
单例模式是设计模式中使用最为普遍的模式之一。它是一种对象创建模式,用于产生一个对象的具体实例,它可以确保系统中一个类只产生一个实例。在Java语言中,这样的行为能带来两大好处:
- 对于频繁使用的对象,可以省略创建对象所花费的实际,这对于那些重量级对象而言,是非常可观的一笔系统开销。
- 由于 new 操作的次数减少,因而对系统内存的使用频率也会降低,这将减轻GC压力,缩短GC停顿时间。
单例模式的参与者非常简单,只有单例类和使用者两个:
| 角色 | 作用 |
|---|---|
| 单例类 | 提供单例的工厂,返回单例 |
| 使用者 | 获取并使用单例类 |
它的基本结构如图2.1所示:
单例模式的核心在于通过一个接口返回唯一的对象实例。一个简单的单例实现如下:
public static class Singleton {
private Singleton() {
//创建单例的过程可能会比较慢
System.out.println("Singleton is create");
}
private static Singleton instance = new Singleton();
public static Singleton getInstance() {
return instance;
}
}
首先单例类必须要有一个private访问级别的构造函数,只有这样,才能确保单例不会在系统中的其他代码中被实例化,这点是相当重要的;其次,instance 成员变量和 getInstance() 方法必须是static的。
这种单例的实现方式非常简单,而且十分可靠。它唯一的不足仅是无法对 instance 实例做延迟加载。加入单例的创建过程很慢,而由于 instance 成员变量的 static 定义的,因此在JVM加载单例类时,单例对象就会被建立,如果此时,这个单例类在系统中还扮演其他角色,那么在任何使用这个单例类的地方都会初始化这个单例变量,而不管是否会被用到。比如单例类作为String工厂,用于创建一些字符串(该类既用于创建单例 Singleton,有用于创建 String 对象):
public static class Singleton {
private Singleton() {
//创建单例的过程可能会比较慢
System.out.println("Singleton is create");
}
private static Singleton instance = new Singleton();
public static Singleton getInstance() {
return instance;
}
public static void createString(){
System.out.println("createString is Singleton");
}
}
当使用 Singleton.createString() 执行任务时,程序输出:
Singleton is create
createString is Singleton
可以看到,虽然此时并没有使用单例类,但它还是被创建出来,这也许是开发人员所不愿意见到的。为了解决这个问题,并以此提高系统在相关函数调用时的反应速度,就需要引入延迟加载机制。
public static class LazySingleton {
private LazySingleton() {
//创建单例的过程可能会比较慢
System.out.println("LazySingleton is create");
}
private static LazySingleton instance = null;
public static synchronized LazySingleton getInstance() {
if (instance == null) {
instance = new LazySingleton();
}
return instance;
}
}
首先,对于静态成员变量 instance 初始值赋予 null,确保系统启动时没有额外的负载;其次在 getInstance() 工厂方法中,判断当前单例是否已经存在,若存在则返回,不存在则再创建实例。这里尤其还要注意,getInstance() 方法必须是同步的,否则在多线程环境下,当线程1正新建单例时,完成赋值操作前,线程2可能判断 instance 为null,故线程2也将启动新建单例的程序,而导致多个实例被创建,故同步关键字是必须的。
使用上例中的单例实现,虽然实现了延迟加载的功能,但和第一种方法相比,它引入同步了关键字,因此在多线程环境中,它的耗时要远远大于第一种单例模式。
for (int i = 0; i < 100000; i++) {
//Singleton.getInstance();
LazySingleton.getInstance();
}
System.out.println("speed:"+(System.currentTimeMillis() - beginTime));
开启5个线程同事完成以上代码的运行,使用第1种类型的单例耗时0ms,而使用第 LazySingleton 却相对耗时约290ms,性能至少相差2个数量级。
为了使用延迟加载引入的同步关键字反而降低了系统性能,是不是有点得不偿失呢?为了解决这个问题,还需要对其进行改进:
public static class StaticSingleton {
private StaticSingleton() {
//创建单例的过程可能会比较慢
System.out.println("StaticSingleton is create");
}
private static class SingletonHolder {
private static StaticSingleton instance = new StaticSingleton();
}
public static StaticSingleton getInstance() {
return singletonHolder.instance;
}
}
在这个实现中,单例模式使用内部类来维护单例的实例,当 StaticSingleton 被加载时,其内部类并不会被初始化,故可以确保当 StaticSingleton 类被载入JVM时,不会初始化单例类,而当 getInstance() 方法被调用时,才会加载 SingletonHolder,从而初始化 instance。同时,由于实例的建立是在类加载时完成,故天生对多线程友好, getInstance() 方法也不需要使用同步关键字。因此,这种实现方式同事兼备以上两种实现的优点。
注意:使用内部类的方式实现单例,既可以做到延迟加载,也不必使用同步关键字,是一种比较完善的实现。
通常情况下,用以上方式实现的单例已经可以确保在系统中只存在唯一实例了。但仍然有例外情况,可能导致系统生成多个实例,比如,在代码中,通过反射机制,强行调用单例类的私有构造函数,生成多个实例。
# 2.1.2 代理模式
代理模式也是一种很常见的设计模式。它使用代理对象完成用户请求,屏蔽用户对真实对象的访问。就如同现实中的代理一样,代理人被授权执行当事人的一些事宜,而无需当事人出面,从第三方角度看,似乎当事人并不存在,因为它只和代理人通信。而事实上代理人也是要有当事人的授权,并且在核心问题上还需要请示当事人。
在现实中,使用代理的情况很普遍,而且原因也很多。比如,当事人因为某些隐私不方便出面,或者当事人不具备某些相关的专业技能,而需要一个职业人员来完成一些专业的操作,也可能由于当事人没有时间处理事务,而聘用代理人出面。
在软件设计中,使用代理模式的意图也很多,比如因为安全原因,需要屏蔽客户端直接访问真是对象;或者在远程调用中,需要使用代理类处理远程方法调用的技术细节(如RMI);也可能是为了提升系统性能,对真是对象进行封装,从而达到延迟加载的目的。
代理模式的结构
角色 作用 主题接口 定义代理类和真是主题的公共对外方法,也是代理类代理真是主题的方法 真实主题 真正实现业务逻辑的类 代理类 用来代理和封装真实主题 Main 客户端,使用代理类和主题接口完成一些工作 以一个简答的示例来阐述使用代理模式实现延迟加载的方法及其意义。假设某客户端软件,有根据用户请求,去数据库查询数据的功能。在查询数据前,需要获得数据库连接,软件开启时,初始化系统的所有类,此时尝试获取数据库连接。单系统有大量的类似操作存在时(比如Xml解析等),所有这些初始化操作的叠加,会使得系统的启动速度变得非常缓慢。为此,使用代理模式,使用代理类,封装对数据库查询中的初始化操作,当系统启动时,初始化这个代理类,而非真是的数据库查询类,而代理类什么都没有做,因此它的构造是相当迅速的。
在系统启动时,将消耗资源最多的方法都使用代理模式分离,就可以加快系统的启动速度,减少用户的等待时间。而在用户真正做查询操作时,再由代理类,单独去加载真实的数据库查询类,完成用户的请求。这个过程就是使用代理模式实现了延迟加载。
注意:代理模式可以用于多种场合,如用于远程调用的网络代理、考虑安全因素的安全代理等。延迟加载只是代理模式的一种应用场景。
延迟加载的核心思想是:如果当前并没有使用这个组件,则不需要真正的初始化它,使用一个代理对象替代它的原有的位置,只要在真正需要使用的时候,才对它进行加载。使用代理模式的延迟加载是非常有意义的,首先,它可以再时间轴上分散系统压力,尤其在系统启动时,不必完成所有的初始化工作,从而加速启动时间;其次,对很多真实主题而言,在软件启动直到被关闭的整个过程中,可能根本不会被调用,初始化这些数据无疑是一种资源浪费。
图2.2显示了使用代理类封装数据库查询类后,系统的启动过程:
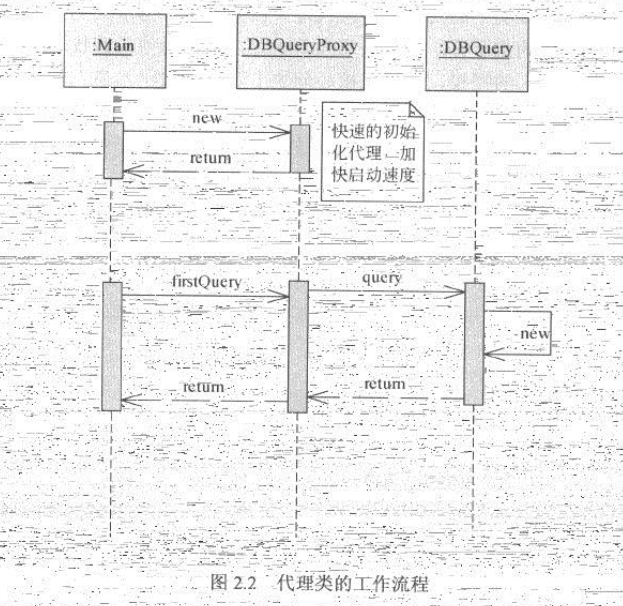
若系统不使用代理模式,则在启动时就要初始化DBQuery对象,而使用代理模式后,启动时只需要初始化一个轻量级的对象DBQueryProxy。
系统的结构图如图2.3所示,IDBQuery 是主题接口,定义代理类和真实类需要对外提供的服务,在本例中定义了实现数据库查询的公共方法request() 函数。DBQuery是真实主题,负责实际的业务操作,DBQueryProxy是DBQuery 的代理类。
代理模式的实现和使用 基于以上设计,IDBQuery的实现如下,它只有一个request()方法。
public intreface IDBQuery{ String request(); }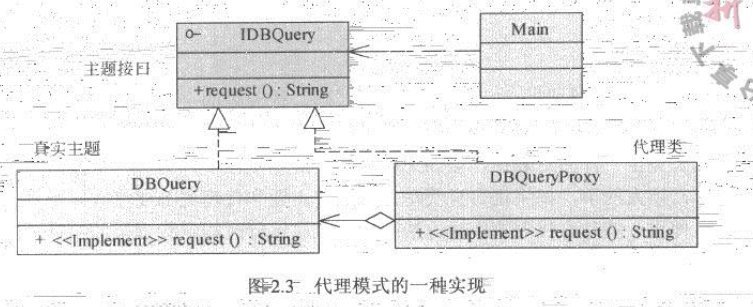
DBQuery实现如下。它是一个重量级对象,构造会比较慢:
public class DBQuery implements IDBQuery{ public DBQuery(){ try{ //模拟数据库连接等耗时操作 Thread.sleep(1000); } catch (InterruptedException e){ e.printStackTrace(); } } @Override public String request(){ retrun "request String"; } }代理类DBQueryProxy 是轻量级对象,创建很快,用于代替DBQuery的位置:
public class DBQueryProxy implements IDBQuery{ private DBQuery real = null; @Override public String request(){ //在真正需要的时候,才创建真实对象,创建过程可能很慢 if(real == null){ real = new DBQuery(); //在多线程环境下,这里返回一个虚假类,类似于Future模式 return real.request(); } } }最后,主函数如下,它引用 IDQuery 接口,并使用代理类工作:
public class Main{ public static void main(String args[]){ //使用代理 IDBQuery query = new DBQueryProxy(); //在真正使用时才创建真实对象 query.request(); } }注意:将代理模式用于实现延迟加载,可以有效地提升系统的启动速度,对改善用户体验有很大的帮助。
动态代理介绍
动态代理是指在运行时,动态生成代理类。
即,代理类的字节码将在运行时生成并载入当前的ClassLoader。与静态代理类相比,动态类有诸多好处。 首先,不需要为真实主题写一个形式上完全一样的封装类,加入主题接口中的方法很多,为每一个接口写一个代理方法也是非常烦人的事,如果接口有变动,则真实主题和代理类都要修改,不利于系统维护; 其次使用一些动态代理的生成方法甚至可以在运行时指定代理类的执行逻辑,从而大大提升系统的灵活性。
注意:动态代理使用字节码动态生成加载技术,在运行时生成并加载类
生成动态代理类的方法很多,如JDK中自带的动态代理、CGLIB、Javassist 或者 ASM库。JDK的动态代理使用简单,它内置在JDK中,因此不需要引入第三方Jar包,但相对功能比较弱。CGLIB和Javassist都是高级的字节码生成库,总体性能比JDK自带的动态代理好,而且功能十分强大。ASM是低级的字节码生成工具,使用ASM已经近乎于在使用 Java bytecode 编程,对开发人员要求最高,当然也是性能最好的一种动态代理生成工具。但ASM的使用实在过于繁琐,而且性能也没有数量级的提升,与CGLIB等高级字节码生成工具相比,ASM程序的可维护性也较差,如果不是在对性能有苛刻要求的场合,还是推荐CGLIB 或者 Javassist。
动态代理实现 以上例中的DBQueryProxy为例,使用动态代理生成动态类,代替上例中的DBQueryProxy。首先,使用JDK的动态代理生成代理对象。JDK的动态代理需要实现一个处理方法调用的Handler,用于实现代理方法的内部逻辑
public class JdkDbQueryHandler implements InvocationHandler{ IDBQuery real = null; @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable{ if(real == null){ //如果是第一次调用,则成成真实对象 real = new DBQuery(); //使用真实主题完成实际的操作 return real.request(); } } }以上代码实现了一个Handler,可以看到,它的内部逻辑和DBQueryProxy是类似的。在调用真实主题的方法前,先尝试生成真实主题对象。接着,需要使用这个Handler生成动态代理对象:
public static IDBQuery creatJdkProxy(){ IDBQuery jdkProxy = (IDBQuery) Proxy.newProxyInstance(ClassLoader.getSystemClassLoader(), new Class[]{IDBQuery.class}, new JdkDbQueryHandler());//指定Handler return jdkProxy; }以上代码生成一个实现了I'DQuery接口的代理类,代理类的内部逻辑由JDKDBQueryHandler 决定。生成代理类后,有 newProxyInstance() 方法返回该代理类的一个实例。至此,一个完整的JDK动态代理就完成了。 CGLIB 和 Javassist的动态代理的使用和JDK的动态代理非常类似。下面,尝试使用CGLIB生成动态代理。CGLIB 也需要实现一个处理代理逻辑的切入类:
public class CglibDBQueryInterceptor implements MethodInterceptor{ IDBQuery real = null; @Override public Object intercept(Object arg0, Method arg1, Object[] arg2, MethodProxy arg3) throws Throwable{ //代理类的内部逻辑,和前文中的一样 if(real == null){ real = new DBQuery(); } return real.requedt(); } }在这个切入对象的基础上,可以生成动态代理:
public static IDBQuery createCglibProxy(){ Enhancer enhancer = new Enhancer(); // 指定切入器,定义代理类逻辑 enhancer.setCallback(new CglibDbQueryInterceptor()); //指定实现的接口 enhancer.setInterfaces(new Class[]{IDBQuery.class}); //生成代理类的实例 IDBQuery cglibProxy = (IDBQuery) enhancer.create(); return cglibProxy; }使用Javassist生成动态代理可以使用两种方式:一种是使用代理工厂创建,另一种通过使用动态代码创建。使用代理工厂创建时,方法与CGLIB类似,也需要实现一个用于代理逻辑处理的Handler:
public class JavassistDynDbQueryHandler implements MethodHandler{ IDBQuery real = null; @Override public Object invoke(Object arg0, Mehtod arg1, Method arg3, Object[] arg3) throws Throwable{ if(real == null){ real = new DBQuery(); return real.request(); } } }以这个Handler为基础,创建动态Javassist代理:
public static IDBQuery createJavassistDynProxy() throws Exception{ ProxyFactory proxyFactory = new ProxyFactory(); //指定接口 proxyFactory.setInterfaces(new Class[]{IDBQuery.class}); Class proxyClass proxyFactory.createClass(); IDBQuery javassistProxy = (IDBQuery) proxyClass.newInstance(); //设置Handler处理器 ((ProxyObject) javassistProxy).setHandler(new JavassistDynDbQueryHandler()); return javassistProxy }Javassist 使用动态Java代码创建代理的过程和前文的方法略有不同。Javassist内部可以通过动态代码,生成字节码。这种方式创建的动态代理可以非常灵活,甚至可以在运行时生成业务逻辑。
public static IDBQuery createJavassistBytecodeDynamicProxy() thows Exception{ ClassPool mPool = new ClassPool(true); //定义类名 CtClass mCtc = mPool.makeClass(IDBQuery.class.getName()+"JavassistBytecodeProxy"); //需要实现的接口 mCtc.addInterface(mPool.get(IDBQuery.class.getName())); //添加构造函数 mCtc.addConstructor(CtNewConstructor.defaultConstructor(mCtc)); //添加类的字段信息,使用动态Java代码 mCtc.addField(CtField.make("public "+IDBQuery.class.getName + "real;",mCtc)); String dbqueryname = DBQuery.class.getName(); //添加方法,这里使用动态Java 代码指定内部逻辑 mCtc.addMethod(CtNewMethod.make("public String request() {if(real == null) {real = new "+dbvqueryname +"();return real.request();}}",mCtc)); //基于以上信息,生成动态类 Class pc = mCtc.toClass(); //生成动态类的实例 IDBQuery bytecodeProxy = (IDBQuery) pc.newInstance(); return bytecodeProxy; }在以上代码中,使用CTField.make() 方法和 CtNewMethod.make() 方法在运行时生成了代理的字段和方法。这些逻辑有Javassist 的CtClass对象处理,将Java代码转换为对应的字节码,并成成动态代理类的实例。
注意: 与静态代理相比,动态代理可以很大幅度的减少代码行数,并提升系统灵活性
在Java中,动态代理类的生产主要设计对ClassLoader的使用。这里以CGLIB为例,简要阐述动态类的加载过程。使用CGLIB生成动态代理,首先需要生成Enhancer类实例,并指定用于处理代理业务的回调类。在Enhancer.create() 方法中,会只用DefaultGeneratorStrategy.generate() 方法生成动态代理类的字节码,并保存再byte数组中。接着使用ReflectUtils.defineClass() 方法,通过反射,调用 ClassLoader.defineClass() 方法,将字节码装载到ClassLoader中,完成类的加载。最后使用 ReflectUtils.newInstance() 方法,通过反射生成动态代理类的实例,并返回该实例。无论使用哪种方法生成动态代理,虽然实现细节不同,单主要逻辑都如图2.4所示:
 前文介绍的几种动态代理的生成方法,性能有一定差异。为了能更好的测试他们的性能,去掉DBQuery类中的Sleep代码,并使用一下方法测试:
前文介绍的几种动态代理的生成方法,性能有一定差异。为了能更好的测试他们的性能,去掉DBQuery类中的Sleep代码,并使用一下方法测试:public static final int CIRCLE = 30000000; public static void main(String[] args) throws Exception{ IDBQuery d = null; long begin = System.CurrentTimeMillis(); //测试JDK动态代理 d = creteJdkProxy(); System.out.println("createJdkProxy:"+d.getClass().getName()); begin = System.CurrentTimeMillis(); for(int i=0;i<CIRCLE;i++){ d.request; } System.out.println("callJdkProxy:"+(System.CurrentTimeMillis()-begin)); begin = System.CurrentTimeMillis(); d=createCglibProxy();//测试DGLIB动态代理 System.out.println("createCglibProxy:"+(System.CurrentTimeMillis()-begin)); System.out.println("CglibProxy:"+d.getClass().getName()); begin = System.CurrentTimeMillis(); for(int i=0;i<CIRCLE;i++){ d.request; } System.out.println("callCglibProxy:"+(System.CurrentTimeMillis()-begin)); begin = System.CurrentTimeMillis(); d=createJavassistDynProxy();//测试Javassist动态代理 System.out.println("createJavassistDynProxy:"+(System.CurrentTimeMillis()-begin)); System.out.println("JavassistDynProxy:"+d.getClass().getName()); begin = System.CurrentTimeMillis(); for(int i=0;i<CIRCLE;i++){ d.request; } System.out.println("callJavassistDynProxy:"+(System.CurrentTimeMillis()-begin)); begin = System.CurrentTimeMillis(); d=createJavassistBytecodeDynamicProxy();//测试Javassist动态代理 System.out.println("createJavassistBytecodeDynamicProxy:"+(System.CurrentTimeMillis()-begin)); System.out.println("JavassistBytecodeDynamicProxy:"+d.getClass().getName()); begin = System.CurrentTimeMillis(); for(int i=0;i<CIRCLE;i++){ d.request; } System.out.println("callJavassistBytecodeDynamicProxy:"+(System.CurrentTimeMillis()-begin)); }以上代码分别生成了4种代理,并对生成的代理类进行高频率的调用,最后输出各代理类的创建耗时,动态类名和方法调用耗时。结果如下:
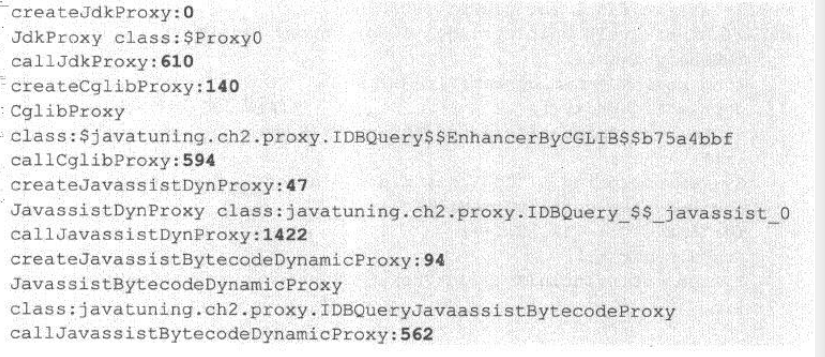
可以看出,JDK的动态类创建过程做快,这是因为这个内置实现中defineClass()方法被定义为native实现,故性能高于其他几种实现。但在代理类的函数调用性能上,JDK的动态代理就不如CGLIB和Javassist的基于动态代码的代理,而Javassist的基于代理工厂的代理实现,代理性能质量最差,甚至不如JDK的实现。在实际开发应用中,代理类的方法调用频率通常要远远高于代理类的实际生成频率(相同类的重复生成会使用cache),故动态代理对象的方法调用性能应该作为性能的主要关注点。
注意:就动态代理的方法调用性能而言,CGLIB和 Javassist的基于动态代码的代理都优于JDK自带的动态代理。此外,JDK的动态代理要求代理类和真实主题都实现同一个接口,而CGLIB和Javassist没有强制要求
Hibernate中代理模式的应用
用代理模式实现延迟加载的一个经典应用就在Hibernate框架中。当Hibernate加载实体Ben时,并不会一次性将数据库所有的数据都装载。默认情况下,它会采取延时加载的机制,以提高系统的性能。Hibernate中的延迟加载主要有两种:一种是属性的延迟加载,二是关联表的延迟加载。这里以属性的延迟加载为例,简单阐述Hibernate是如何使用动态代理的。
假定有用户模型:
public class User implements Serializable{
private Integer id;
private String name;
private int age;
//省略getter 和 setter
}
使用一下代码,通过Hibernate加载一条User信息:
//从数据库载入ID为1的用户
User u = (User) HibernateSessionFaction.getSession().load(User.class,1);
//打印类名称
System.out.println("Class name:"+u.getClass().getName());
//打印父类名称
System.out.println("Supper Class name:"+u.getClass().getSuperclass().getName());
//实现的所有接口
Class[] ins = u.getClass().getInterfaces();
for(Class cls:ins){
System.out.println("interface:"+cls.getName());
}
System.out.println(u.getName());
以上代码中,在session.load()方法后,首先输出了User的类名、它的超类、User实现的接口,最后输出调用User的getName()方法取得的数据库数据。这段程序的输出如下:

仔细观察这段输出,可以看到,session的载入类并不是之前定义的User类,而是名叫javatuning.ch2.proxy.hibernate.User$$EnhancerByCGLIB$$96d498bed的类。从名称上可以推测,它是使用CGLIB的Enhancer类生成的动态类。该类的父类才是应用程序定义的User类。
此外,它实现了HIbernateProxy接口。由此可见,Hibernate使用一个动态代理子类替代用户定义的类。这样在载入对象时,就不必初始化对象的所有信息,通过代理,拦截原有的getter方法,可以再真正使用对象数据时,才去数据库加载实际的数据,从而提升系统性能。由这段输出的顺序来看,也正是这样,在getName()被调用之前,Hibernate从未输出过一条SQL语句。这表示:User对象被加载时,根本就没有访问数据库,而在getName() 方法被调用时,才真正完成了数据库操作。
注意:Hibernate框架中对实体类的动态代理是代理模式用于延迟加载的经典实现。
# 2.1.3 享元模式
享元模式是设计模式中少数几个以提高系统性能为目的的模式之一。
它的核心思想是:如果再一个系统中存在多个相同的对象,那么只需共享一份对象的拷贝,而不必为一次使用都创建新的对象。在享元模式中,由于需要构造和维护这些可以共享的对象,因此,常常会出现一个工厂类,用于维护和创建对象。
享元模式对性能提升的主要帮助有两点:
可以节省重复创建对象的开销,因为被享元模式维护的相同对象只会被创建一次,当创建对象比较耗时时,便可以节省大量时间。
由于创建对象的数量减少,所以对系统内存的需求也减小,这将使得GC的压力也响应的降低,今儿使得系统拥有一个更健康的内存结构和更快的反应速度。
享元模式的主要角色有享元工厂、抽象享元、具体享元类和主函数几部分组成。他们的功能如下:
角色 作用 享元工厂 用以创建具体享元类,维护相同的享元对象。它保证相同的享元对象可以被系统共享。即,其内部使用了类似单例模式的算法,当请求对象已经存在时,直接返回对象,不存在时,再创建对象。 抽象享元 定义需共享的对象的业务接口。享元类被创建出来总是为了实现某些特定的业务逻辑,而抽象享元便定义这些逻辑的语义行为。 具体享元类 实现抽象享元类的接口,完成某一具体逻辑 Main 使用享元模式的组件,通过享元工厂取得享元对象 基于以上角色,享元模式的结构如下:
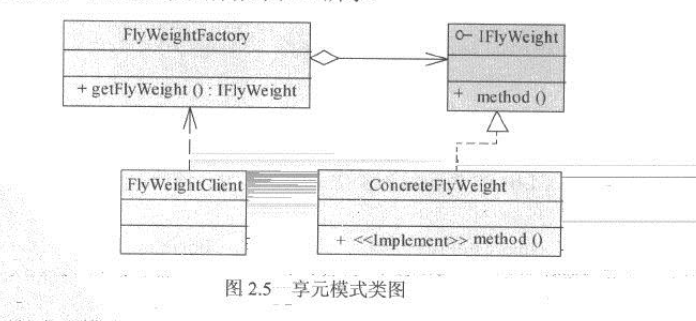
享元工厂是享元模式的核心,它需要确保系统可以共享相同的对象。一般情况下,享元=工厂会维护一个对象列表,当任何组件尝试获取享元类时,如果请求的享元类货已经被创建,则直接返回已有的享元类;若没有,则创建一个新的享元对象,并将它加入到维护队列中。
注意:享元模式是为数不多的、只为提升系统性能而生的设计模式。它的主要作用就是复用大对象(重量级对象),以节省内存空间和对象创建时间。
享元模式的一个经典应用是在SAAS系统中。SAAS即 Software As A Service,是目前比较流行的一中软件应用模式。
以一个人事管理系统的SAAS软件为例,假设公司甲、乙、丙均为这个SAAS系统的用户,则定义每个公司为这套系统的一个租户。每个公司(租户)又各有100个员工。如果这些公司的所有员工都可以登录这套系统查看自己的收入情况,并且为了系统安全,每个公司(租户)都用友自己独立的数据库。为了使系统的设计最为合理,在这种情况下,便可以使用享元模式为每个租户分别提供工资查询的接口,而一个公司下的所有员工可以共享一个查询(因为一个租户下所有的员工数据都存放在一个数据库中,它们共享数据库连接)。这样,系统只需要3个享元实例,就足以应付300个员工的查询请求了。系统的结构图如下:
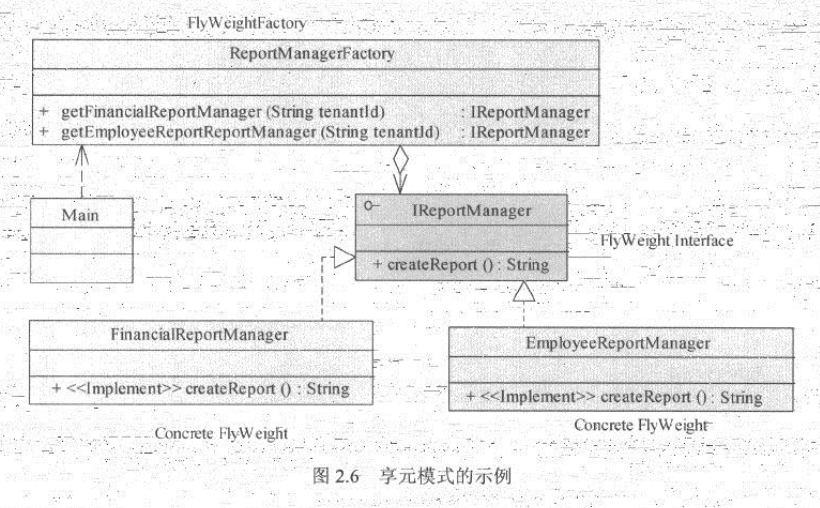
ReportManagerFactory 为享元工厂,负责创建具体的报表工具,它确保每个公司下所有的员工,都共享一个具体的享元实例(FinancialReportManager或者EmployeeReportManager)。这样,当公司甲的两个员工登录,进行财务查询时,系统不必为两个员工都新建FinancialReportManager,而可以让他们共享一个FinancialReportManager实例。
通过这个示例,还可以进一步 了解享元工厂和对象池的一个重要区别。在一个对象池中,所有的对象都是等价的,任意两个对象在任何使用场景中都可以被对象池中的其他对象代替。而在享元模式中,享元工厂所维护的所有对象都是不同的,任何两个对象间不能互相代替。如本例中,为公司甲创建的FinancialReportManagerA 和为公司乙创建的FinancialReportManagerB 分别对应了后台各自不同的数据库,因此两者是不可相互替代的。
注意:享元模式和对象池的最大不同在于:享元对象是不可相互替代的,他们各自都有各自的含义和用途;而对象池中的对象都是等价的,如数据库连接池中的数据库连接。
本例中享元对象接口的实现如下,它用于创建一个报表。即,所有的报表生成类将作为享元对象在一个公司中共享。
public interface IReportManager{ public String createReport(); }以下是两个报表生成的实例,分别对应员工财务收入报表和员工个人信息报表。他们都是具体的享元类。
//财务报表 public class FinancialReportManager implements IReportManager{ protected String tenantId = null; public FinancialReportManager(String tenantId){ this.tenantId = tenantId; } @Override public String createReport(){ return "This is a financial report"; } } //员工报表 public class EmployeeReportManager implements IReportManager{ protected String tenantId = null; public EmployeeReportManager(String tenantId){ this.tenantId = tenantId; } @Override public String createReport(){ return "This is a employee report"; } }最为核心的享元工厂类实现如下,它也是享元模式的精髓所在。它确保同一个公司(租户)使用相同的对象产生报表。这是相当有意义的,否则系统可能会为每个员工生成各自的报表对象,导致系统开销激增。
public class ReportManagerFactory{ Map<String,IReportManager> financialReportManager = new HashMap<>(); Map<String,IReportManager> employeeReportManager = new HashMap<>(); public IReportManager getFinancialReportManager(String tenantId){ IReportManager r = financialReportManager.get(tenantId); if(r == null){ r = new FinancialReportManager(tenantId); financialReportManager.put(tenantId,r); } return r; } public IReportManager getEmployeeReportManager(String tenantId){ IReportManager r = employeeReportManager.get(tenantId); if(r == null){ r = new FinancialReportManager(tenantId); employeeReportManager.put(tenantId,r); } return r; } }使用享元模式的方法如下:
public static void main(String[] args){ ReportManagerFactory rmf = new ReportManagerFactory(); IReportManager rm = rmf.getFinancialReportManager("A"); System.out.println(rm.createReport()); }ReportManagerFactory 作为享元工厂,以租客的ID为索引,维护了一个享元对象的集合,它确保相同租客的请求都返回同一个享元实例,确保享元对象的有效复用。
# 2.1.4 装饰者模式
装饰者模式拥有一个设计非常巧妙的结构,它可以动态添加对象功能。在基本的设计原则中,有一条重要的设计准则叫做合成/聚合复用原则。根据该原则的思想,代码复用应该尽可能使用委托,而不是使用继承。因为继承是一种紧密耦合,任何父类的改动都会影响其子类,不利于系统维护。而委托则是松散耦合,只要接口不变,委托类的改动并不会影响其上层对象。
装饰者模式就充分运用了这种思想,通过委托机制,复用系统中的各个组件,在运行时,可以将这些功能组件进行叠加,从而构成一个“超级对象”,使其拥有所有这些组件的功能。而各个子功能模块,被很好的维护在各个组件的相关类中,拥有整洁的系统结构。
注意:装饰者模式可以有效分离性能组件和功能组件,从而提升模块的可维护性并增加模块的复用性。
装饰者模式的基本结构图如图:
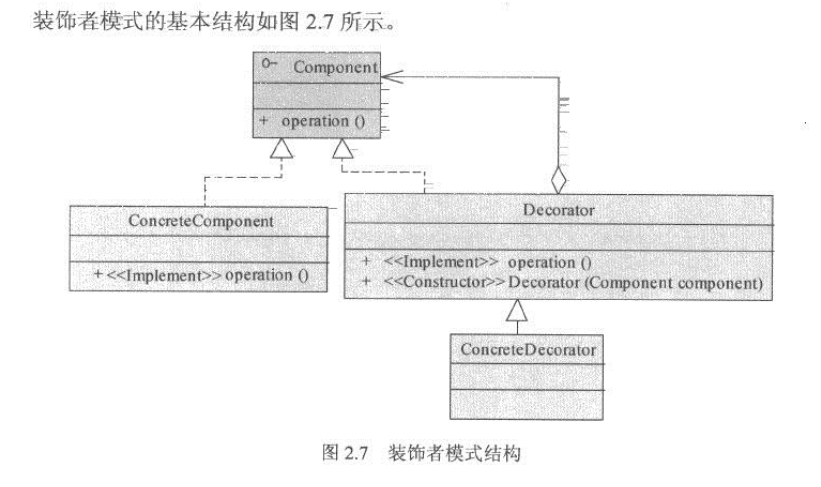
装饰者(Decorator)和被装饰者(ConcreteComponent)拥有相同的接口Component。被装饰者通常是系统的核心组件,完成特定的功能目标。而装饰者则可以再被装饰者的方法前后,加上特定的前置处理和后置处理,增强被装饰者的功能。
装饰者模式的主要角色如下:
| 角色 | 作用 |
|---|---|
| 组件接口 | 组件接口是装饰者和被装饰者的超类或者接口。它定义了被装饰者的核心功能和装饰者需要加强的功能点 |
| 具体组件 | 具体组件实现了组件接口的核心方法,完成某一个具体的业务逻辑。它也是被装饰的对象 |
| 装饰者 | 实现组件接口,并持有一个具体的被装饰者对象 |
| 具体装饰者 | 具体实现装饰的业务逻辑,即实现了杯分离的各个增强功能点。各个具体装饰者是可以互相叠加的,从而可以构成一个功能更强大的组件对象。 |
装饰者模式的一个典型案例就是对输出结果进行增强。比如,现在需要将某一结果通过HTML进行发布,那么首先就需要将内容转化为一条HTML文本。同时,由于内容需要再网络上通过HTTP流传,故,还需要为其增加HTTP头。当然,作为一个更复杂的情况,可能还需要为其安置TCP头等。
装饰者模式的核心思想在于:无需将所有的逻辑,即,核心内容构建、HTML文本构造和HTTP头生成等3个功能模块粘合在一起实现。通过装饰者模式,可以将它们分解为3个几乎完全独立的组件,并在使用时灵活的进行装配。为实现这个功能,可以使用如下结构:
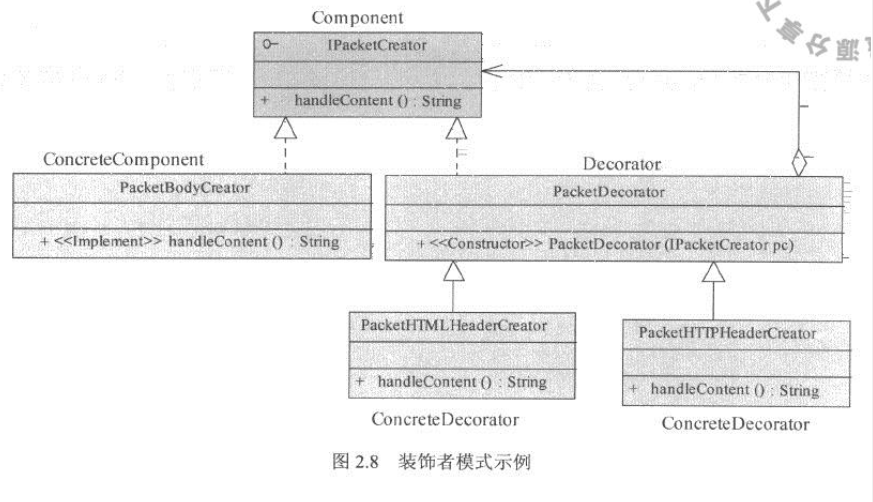
IPacketCreator 即装饰接口,用于处理具体的内容。PacketBodyCreator 是具体的组件,它的功能是构造要发出信息的核心内容,但是它不负责将其构造成一个格式完整、可直接发布的数据格式。PacketHttpHeaderCreator 负责对给定的内容加上HTTP头部,PacketHtmlHeaderCreator负责将给定的内容格式化为HTML文本。如图2.8所示,3个功能模块相对独立且分离,易于系统维护。
IPacketCreator 的实现很简单,它是一个但方法的接口
public interface IPacketCreator {
//用于内容处理
public String handleContent;
}
PacketBodyCreator 用于返回数据保的核心数据:
public class PacketBodyCreator implements IPacketCreator{
@Override
public String handleContent(){
//构造核心数据,但不包括格式
return "Content of Packet";
}
}
PacketCreator 维护核心组件Component对象,它负责告知其子类,其核心业务逻辑应该全权委托 component 完成,自己仅仅是做增强处理。
public abstract class PacketDecorator implements IpacketCreator{
IPacketCreator component;
public PacketDecorator (IPacketCreator c){
component = c;
}
}
PacketHtmlHeaderCreator 是具体的装饰器,它负责对核心发布的内容进行Html格式化操作。需要特别注意的是,它委托了具体组件Component进行核心业务处理。
public class PacketHtmlHeaderCreator extends PacketDecorator{
public PacketHtmlCreator(IPacketCreator c){
super(c);
}
//将给定数据封装成HTML
@Override
public String handleContent(){
StringBuffer sb = new StringBuffer();
sb.append("<html>");
sb.append("<body>");
sb.append(component.handleContent());
sb.append("</body>");
sb.append("</html>");
return sb.toString();
}
}
PacketHttpHeaderCreator 与PacketHtmmlHeaderCreator类似,但是它完成数据包HTTP头部的处理。其余业务处理依然交由内部的Component完成。
public class PacketHttpHeaderCreator extends PacketDecorator{
public PacketHttpHeaderCreator (IPacketCreator c){
super(c);
}
//对给定数据加上HTTP头信息
@Override
public String handleContent(){
StringBuffer sb = new StringBuffer();
sb.append("Cache-control:no-cache\n");
sb.append("Date:Mon,31Dec201204:25:57GMT\n");
sb.append(component.handleContent());
return sb.toString();
}
}
对于装饰者模式,另外一个指的关注的地方是它的使用方法。在本例中,通过层层构造和组装这些装饰者和被装饰者到一个对象中,使其有机的结合在一起工作。
public static void main(String[] args){
IPacketCreator pc = new PacketHttpHeaderCreator(
new PacketHtmlheaderCreator(
new PacketBodyCreator()));
System.out.println(pc.handleContent());
}
可以看到,通过装饰者的构造函数,将被装饰对象传入。本例中,共生成3个对象实例,作为核心组件的PacketBodyCreator最先被构造,其次是PacketHtmlHeaderCreator,最后才是PacketHttpHeaderCreator。
这个顺序表示,首先由PacketBodyCreator对象去生成核心发布内容,接着由PacketHtmlHeaderCreator对象度这个内容进行处理,将其转换为HTML,最后由PacketHttpHeaderCreator对PacketHtmlHeaderCreator的输出安置HTTP头部。程序运行输出如下:
Cache-Control:no-Cache
Date:Mon,31Dec201204:25:57GMT
<html><body>Content of Packet</body></html>
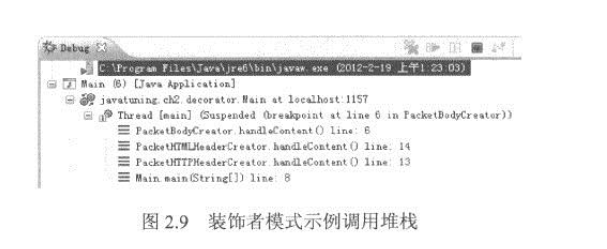
图2.9是本例的调用堆栈,从调用堆栈中,读者应该可以更容易的理解各个组件的相互关系。
在JDK的实现中,有不少组件也是用装饰者模式实现。其中,一个最典型的例子就是OutputStream 和 InputStream 类族的实现。以OutputStream为例,OutputStream对象提供的方法比较简单,功能也比较弱,但通过各种装饰者的增强,OutputStream 对象可以被赋予强大的功能。
图2.10显示了以OutputStream 为核心的装饰者模式的实现。其中FileOutputStream为:
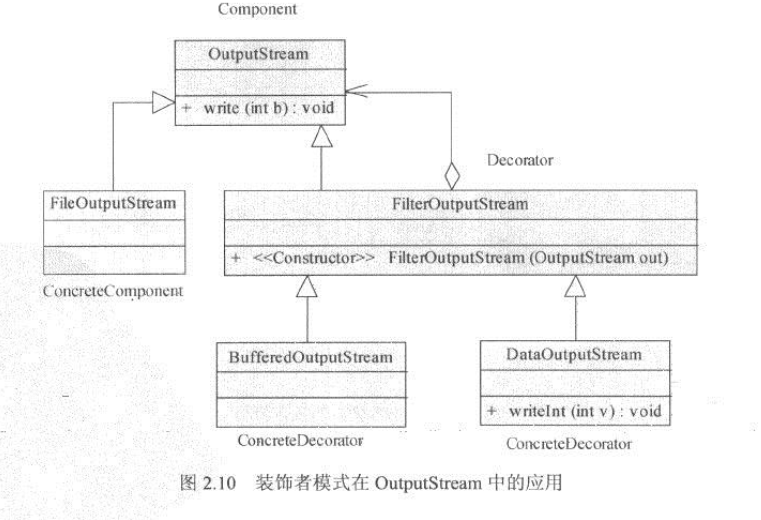
系统的核心类,它实现了想文件写入数据。使用DataOutputStream可以在FileOutputStream的基础上,增加对多种数据类型的写操作支持,而BufferedOutputStream装饰器,可以对FileOutputStream增加缓冲功能,优化I/O的性能。以BufferedOutputStream为代表的性能组件,是将性能模块和功能模块分离的一种典型实现。
public static void main(String[] args) throws Exception{
//生成一个有缓冲功能的流对象
DataOutputStream dout = new DataOutputStream(
new BufferedOutputStream(new FileOutputStream("C://a.txt")));
//没有缓冲功能的流对象
DataOutputStream dout = new DataOutputStream(
new FileOutputStream("C://a.txt"));
long begin = System.currentTimeMillis();
for(int i=0;i<10000;i++){
dout.writeLong(i);
}
System.out.println("speed:"+(System.currentTimeMillis() - begin));
}
以上代码显示FileOutputStream 的典型应用。加粗部分是两种简历OutputStream 的方法,第一种加入了性能组件 BufferedOutputStream,第二种则没有。因此,第一种方法的 OutputStream 拥有更好的 I/O性能。
**注意:JDK中OutputStream和 InputStream 类族的实现是装饰者模式的典型应用。通过嵌套的方式不断的将对象聚合起来,最终形成了一个超级对象,并使之拥有所有相关对象的功能。
下面来看一下装饰者模式如何通过性能组件增强I/O性能。在运行时,工作流程如图2.11所示:
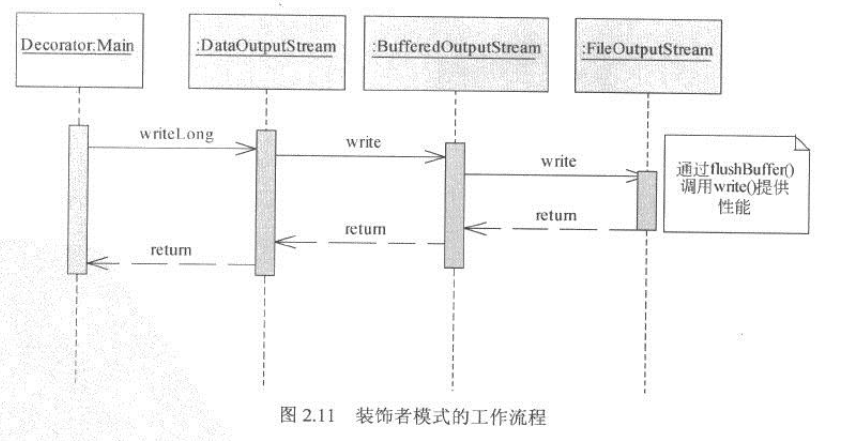
在FileOutputStream.write()的调用之前,会首先调用BufferedOutputStream.write(),它的实现如下:
public synchroized void write(byte[] b,int off,int len) throws Exception{
if (len >= buf.length){//如果要写入的数据量大于缓存容量
flushBuffer();//写入所有缓存
out.write(b,off,len);//直接将数据写入文件
return;
}
if(len > buf.length-count){
flushBuffer();
}
System.arrayCopy(b,off,buf,count,len);
count += len;
}
private void flushBuffer() throws Exception{
if (count > 0){
out.write(buf,0,count);//这里的out对象是 FileOutputStream
count = 0;
}
}
可以看到,并不是每次 BufferedOutputStream.write() 调用都会去磁盘写入数据,而是将数据写入缓存中,当缓存满时,才调用FileOutputStream.write() 方法,实际写入数据。以此实现性能组件和功能组件的完美分离。
# 2.1.5 观察者模式
观察者模式是非常常用的一种设计模式。在软件系统中,当一个对象的行为依赖于另外一个对象的状态时,观察者模式就相当有用。若不使用观察者模式提供的通用结构,而需要实现其类似的功能,则只能在另一个线程中不停的监听对象所依赖的状态。在一个复杂系统中,可能因此开启很多线程来实现这一功能,这将使系统的性能产生额外的负担。观察者模式的意义就在此,它可以在单线程中,使某一对象,及时得知自身所依赖的状态的变化。观察者模式的景点结构如图:
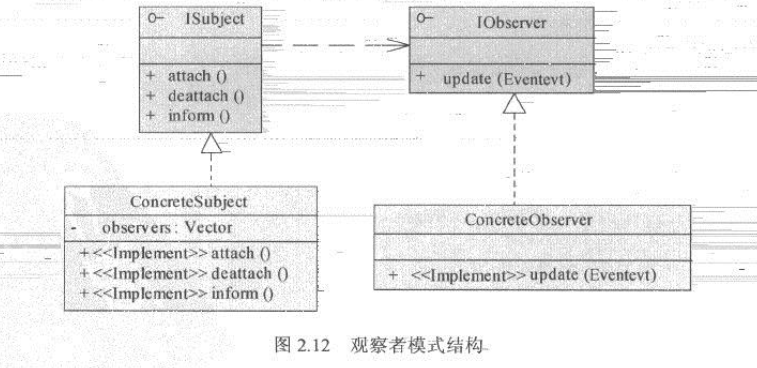
ISubject是被观察对象,它可以增加或者删除观察者。IOberver是观察者,它依赖ISubject的状态编号。当ISubject状态发生变化时,会通过inform()方法通知观察者。
注意:观察者模式可以用于事件监听、通知发布等场合。可以确保观察者在不使用轮询监控的情况下,及时收到相关消息和事件。
观察者模式的主要角色如下:
| 角色 | 作用 |
|---|---|
| 主题接口 | 指被观察的对象。当其状态发生改变或某事件发生时,它会将这个变化通知观察者。它维护了观察者所需依赖的状态 |
| 具体主题 | 具体主题实现了主题即可中的方法。如新增观察者、删除观察者和通知观察者。其内部维护一个观察者列表 |
| 观察者接口 | 观察者接口定义了观察者的基本方法。当依赖状态发生改变时,主题接口就会调用观察者的update()方法 |
| 具体观察者 | 实现观察者接口的update(),具体处理当被观察者状态改变或某一时间发生时的业务逻辑 |
主题接口的实现如下:
public interface ISubject{
void attach(IObserver observer); //添加观察者
void detach(IObserver observer);//删除观察者
void inform()//通知所有观察者
}
观察者接口如下:
public interface IObserver{
void update(Event evt); //更新观察者
}
一个具体的主题实现,注意,它维护了观察者队列,提供了增加和删除观察者的方法,并通过其inform()通知观察者。
public class ConcreteSubject implements ISubject{
Vector<IObserver> observers = new Vector<IObserver>();
public void attach(IObserver observer){
observers.addElement(observer);
}
public void detach(IObserver observer){
observers.removeElement(observer);
}
public void inform(){
Event evt = new Event();
for(IObserver ob:observers){
ob.update(evt);//注意:在这里通知观察者
}
}
}
一个具体的观察者实现如下,当其监听的状态发生改变时,update()方法就会被主题回调,今儿可以在观察者内部进行业务逻辑处理。
public class ConcreteObserver implements IObserver{
public void update(Event t){
System.out.println("observer receives information");
}
}
观察者模式是如此常用,以至于JDK内部就已经为开发人员准备了一套观察者模式的实现。它位于java.util 包中,包括 java.util.Observable 类 和 java.util.Observer 接口,他们的关系如图2.13所示:
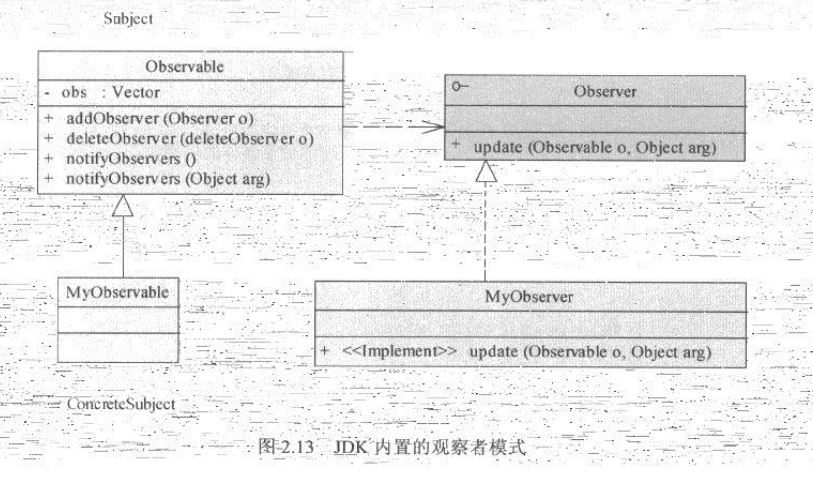
在java.util.Observable类中,已经实现了主要的功能,如增加观察者、删除观察者和通知观察者,开发人员可以直接通过继承Observable使用这些功能。java.util.Observable接口是观察者接口,他的update()方法会再java.util.Observable的notifyObserver()方法中被回调,以获得最新的状态变化。通常在观察者模式中Observer接口总是应用程序的核心扩展对象,具体的业务逻辑总是会被封装在update()方法中。
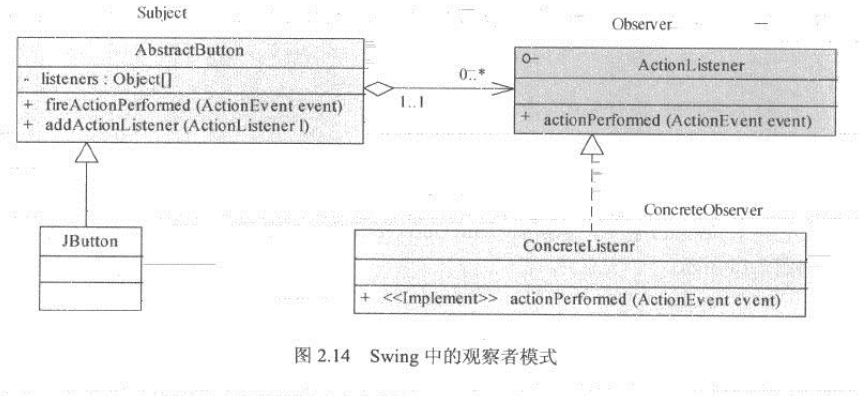
在JDK中,观察者模式也得到了普遍的应用。一个最典型的应用便是Swing框架的JButton实现,它的事件处理机制如图2.14所示。
JButton继承自AbstractButton,在AbstractButton中维护了一组监听器,他们就扮演着被观察者的角色。而AbstractButton本身就是被观察对象。监听器ActionListener并不是依靠循环监听去获取按钮何时被单机,而是当按钮被单击时,通过AbstractButton的fireActionPermed()方法回调ActionListener.actionPerformed()方法实现。基于这种结构,在应用程序开发时,只需要简单的实现ActionListener接口(也就是Observer),并将其添加到按钮(Subject角色)的观察者列表中,那么当单机时间发生,就可以自动触发监听器的业务处理函数。下面观察者模式的角度分析一段按钮单击处理的代码:
//具体的观察者
public static class BtnListener implements ActionListener{
//在fireActionPerformed()中被回调
@Override
public void actionPerformed(ActionEvent e){
System.out.println("click");//按钮单击时,由具体观察者处理业务
}
}
public static void main(String[] args){
JFrame p = new JFrame();
JButton btn = new JButton("Click Me");//新建具体主题
btn.addActionListener(new BtnListener());//在具体主题中,加入观察者
p.add(btn);
p.pack();
p.setVisible(true);
}
当按钮被单击时,通过被观察对象通知观察者,以下是AbstractButton 中的一段事件处理代码,显示了杯观察对象如何通知观察者:
public void fireActionPerformed(ActionEvent event){
//这里就是应用层实现的ActionListener
Object[] listeners = listenerList.getListenerList();
ActionEvent e = null;
for(int i=listeners.length-2;i>0;i-=2){
if(listeners[i] == ActionListener.class){
if(e == null){
String actionCommand = event.getActionCommand();
if(actionCommand == null){
actionCommand = getActionCommand();
}
//构造事件参数,告诉应用层是何种事件发生
e = new ActionEvent(AbstractButton.this,
ActionEvent.ACTION_PERFORMED,
actionCommand,
event.getWhen(),
event.getModifiers());
}
//回调应用层的实现
((ActionListener)listeners[i+1]).actionPerformed(e);
}
}
}
# 2.1.6 Value Object模式
在J2EE软件开发中,通常会对系统模块进行分层。展示层主要负责数据的展示,定义数据库的UI组织模式;业务逻辑层负责具体的业务逻辑处理;吃就吃通常指数据库以及相关操作。在一个大型系统中,这些层次很有可能被分离,并部署在不同的服务器上。而在两个层次之间,可能通过远程调用RMI等方式进行通信。如果2.15所示,展示层组件作为RMI的客户端,通过中间的业务逻辑层取得一个订单(Order)的信息。假设一个订单由客户名、商品名和数量构成,那么一次交互过程可能由图2.15所描述的这样,RMI的客户端会与服务端进行3次交互,依次取得这些信息。
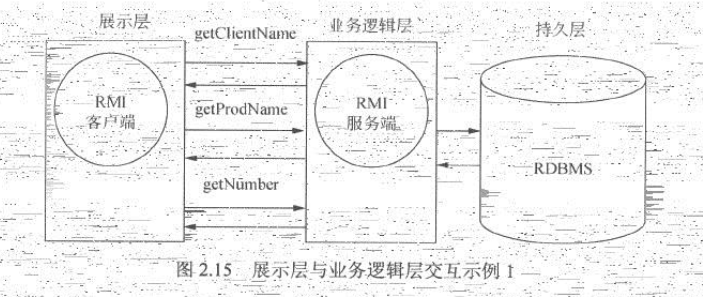
基于以上模式的通信方式是一种可行的解决方案,但是它存在两个严重的问题:
对于获取一个订单对象而言,这个操作模式略显繁琐,且不具备较好的可维护性。
前后累积进行3次客户端与服务端的通信,性能成本较高。
为了解决这两个问题,就可以使用Value Object模式。Value Object模式提倡将一个对象的各个属性进行封装,将封装后的对象在网络中传递,从而使系统拥有更好的交互模型,并且减少网络通信数据,从而提高系统性能。使用Value Object模式对以上结构进行改良,定义对象Order,由Order对象维护客户名、商品名和数量等信息,而Order对象也就是Value Object,它必须是一个可串行化(序列化)的对象。将Value Object模式应用到本例中,便可以得到如图2.16所示的结构。
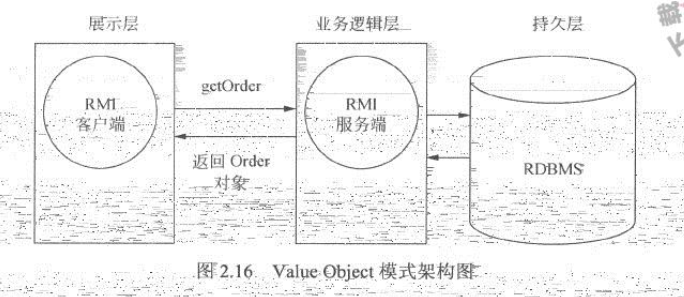
在基于Value Objecct 模式的结构中,为了获得一份订单信息,只需要进行一次网络通信,缩短了数据存取的响应时间,减少了网络数据流量。
注意:使用ValueObject模式可以有效减少网络交互次数,提高远程调用方法的性能,也能使系统接口具有更好的可维护性。
RMI服务端的接口实现如下,其中getOrder() 方法取得一个Value Object,其他方法均取得Order对象的一部分信息:
public interface IOrderManager extends Remote{ // value Object模式 public Order getOrder(int id) throws RemoteException; public String getClientName(int id) throws RemoteException; public String getProdName(int id) throws RemoteException; public int getNumber(int id) throws RemoteException; }一个最简单的IOrderManager的实现,它什么也没有做,只是返回数据:
public class OrderManager extends UnicastRemoteObject implements IOrderManager{ protected OrdreManager() throws RemoteException{ super(); } private static final long serialVersionUID = -1717013007581295639L; @Override public Order getOrder(int id) throws RemoteException{ //返回订单信息 Order o = new Order(); o.setClientName("billy"); o.setNumber(20); o.setProdunctName("desk"); return o; } @Override public String getClientName(int id) throws RemoteException{ //返回订单的客户名 return "billy"; } @Override public String getProdName(int id) throws RemoteException{ //返回商品名 return "desk"; } @Override public int getNumber(int id) throws RemoteException{ //返回数量 return 20; } }作为Value Object 的Order 对象实现如下:
public class Order implements java.io.Serializable{ private int orderId; private String clientName; private int number; private String produnctName; //省略 getter setter 方法 }业务逻辑层注册并开启RMI服务器:
public class OrderManagerServer{ public static void main(String[] args){ try{ //注册RMI端口 LocateRegistry.createRegistry(1099); //RMI远程对象 IOrderManager usermanager = new OrderManager(); //绑定RMI对象 Naming.rebind("OrderManager",usermanager); System.out.println("OrderManager is ready"); }catch(Exception e){ System.out.println("OrdreManager server failed:"+e); } } }客户端的测试代码如下,它分别展示了使用Value Object模式封装数据和不使用Value Object模式的性能差异:
public static void mian(String[] args){ try{ IOrderManager usermananger = (IOrderManager) Naming.lookup("OrderManager"); long begin = System.currentTimeMillis(); for(int i=0;i<1000;i++){ //Value Object模式 usermanager.getOrder(i); } System.out.println("speed:"+(System.currentTimeMillis()-begin)); begin = System.currentTimeMillis(); for(int i=0;i<1000;i++){ //通过多次交互获取数据 usermanager.getClientName(i); usermanager.getNumbere(i); usermanager.getProdName(i); } System.out.println("3 Method call speed:"+(System.currentTimeMillis()-begin)); }catch(Exception e){ System.out.println("OrdreManager exception:"+e); } }结果显示,使用getOrder()方法相对耗时469ms,而使用连续3次离散的远程调用耗时766ms。由此可见,对传输数据进行有效的封装,可以明显提升远程方法调用的性能。
# 2.1.7 业务代理模式
Value Object 模式是将远程调用传递数据封装在一个串行化的对象中进行传输,而业务代理模式则是将一组由远程方法调用构成的业务流程,封装在一个位于展示层的代理中。比如,如果用户需要修改一个订单,订单修改操作可细分为3个子操作:
校验用户
获取旧的订单信息
更新订单
系统结构如图:2.17 所示:
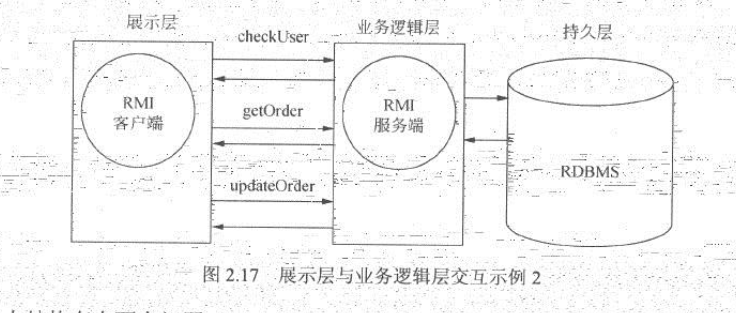
以上结构存在两个问题:
当展示层存在大量并发线程时,这些线程都会直接进行远程方法调用,进而会加重网络负担。
由于缺乏对订单修改操作流程的有效封装,如果将来流程发生变化,那么展示层组件需要修改。
为了有效的解决以上两个问题,可以在展示层中加入业务代理对象,业务代理对象负责和远程服务器通信,完成订单修改操作。而业务代理对象本身只暴露简单的updatEOrder()订单修改操作供展示层组件使用,修改后的结构如图2.18所示:
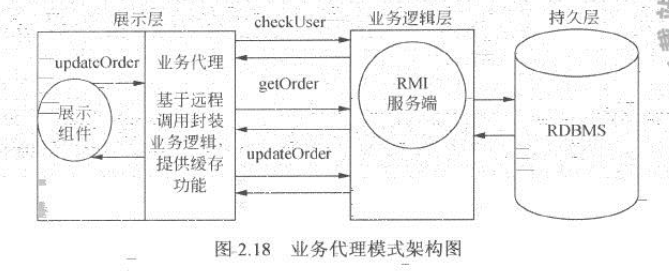
注意:业务代理模式将一些业务流程封装在前台系统,为系统性能优化提供了基础平台。在业务代理中,不仅可以复用业务流程,还可以视情况为展示层组件提供缓存等功能,从而减少远程方法调用次数,降低系统压力。
这种结构体现了业务代理模式的核心思想。由于该业务代理对象被所有的展示层请求线程和多个客户端共享,故系统将会有较好的可维护性。如果业务流程发生变化,只需要简单的修改业务代理对象暴露的updateOrder()方法即可。除此之外,通过业务代理对象,可以更容易的再讴歌线程或者客户端请求之间共享数据,从而有效的利用缓存,减少远程调用测试,提高系统性能。
一个未使用业务代理模式的展示层实现可能如下所示:
public static void main(String[] args){
try{
IOrderManager usermananger = (IOrderManager) Naming.lookup("OrderManager");
if(usermanager.checkUser(1)){
//所有的远程调用都会被执行,当并发量较大时,严重影响性能
Order o = usermanager.getOrder(1);
o.setNumber(10);
usermanager.updateOrder(o);
}
}catch(Exception e){
System.out.println("OrdreManager exception:"+e);
}
}
而使用了业务代理后,展示层组件可以优化成:
public static void main(String[] args){
BusinessDelegate bd = new BussinessDelegate();
Order o = bd.getOrder(11);
o.setNumber(11);
bd.updateOrdre(o);
}
在业务代理对象 BusinessDelegate 中,可以增加缓存,从而直接减少远程调用的次数。以下是一段不完整的实例代码,但足以说明问题:
public class BusinessDelegate {
IOrderManager usermanager =null;
//封装远程方法调用流程
public BusinessDelegate(){
usermanager = (IOrderManager) Naming.lookup("OrderManager");
}
public boolean checkUserFromCache(int id){
return true;
}
public boolean checkUser(int id)throws RemoteException{
//当前对象被多个客户端共享,可以再本地缓存中校验用户
if(!checkUserFromCache(id)){
return usermanager.checkUser(1);
}
return true;
}
public Order getOrderFromCache(int id){
return true;
}
public Order getOrder(int oid)throws RemoteException{
//可以再本地缓存中获取订单,减少远程调用次数
Order order = getOrderFromCache(oid)
if(order == null){
return usermanager.getOrder(oid);
}
return order;
}
//暴露给展示层的方法,封装了业务路程,可能在缓存中执行
public boolean updateOrder(Order order) throws Exception{
if(checkUser(1)){
Order order = getOrder(1);
o.setNumber(10);
usermanager.updateOrder(order);
}
return true;
}
}